
automation-de.com
17
'22
Written on Modified on
Mouser News
Keine Daten mehr verschieben, sondern den Algorithmus – Implementierung von Computational Storage
Angesichts des immer stärkeren Einsatzes von neuronalen Netzen im Bereich Machine Learning müssen auch immer größere Datenmengen verarbeitet werden. Aus IT-Sicht ging der Trend schon immer dahin, die Daten dorthin zu verlagern, wo sie von einem Algorithmus verarbeitet werden.

Große Datensätze von bis zu 1 PB werden jedoch immer mehr zur Norm. Wenn man sich vor Augen führt, dass der für die Verarbeitung zuständige Algorithmus vielleicht nur einige Dutzend Megabyte groß ist, wird das Konzept der Datenverarbeitung in der Nähe des Speichergeräts immer wichtiger. Dieser Artikel befasst sich mit den Konzepten und der Architektur, die hinter dieser so genannten Computational Storage stehen, und erläutert, warum ein Speicherprozessor (Computational Storage Processor, CSP) die Hardware beschleunigt und Leistungsvorteile für zahlreiche rechenintensive Aufgaben bietet, ohne den Host-Prozessor zu überlasten.
Tendenz steigend: Datensätze werden immer größer
In den letzten Jahren hat der Einsatz von Algorithmen für neuronale Netze dramatisch zugenommen, insbesondere in den Bereichen Automobil, Industrie, Sicherheit und Consumer-Anwendungen. Einige Algorithmen, wie z. B. die in Edge-basierten IoT-Sensoren, benötigen nur wenig Code und verarbeiten nur sehr wenige Daten. Der Einsatz von Algorithmen für Machine Learning im Edge-Bereich nimmt jedoch exponentiell zu, da die Funktionen von eingebetteten Mikrocontrollern mit geringem Stromverbrauch und die Fähigkeiten von neuronalen Netzen immer besser werden. Industrie- und Automotive-Anwendungen konzentrieren sich stark auf die Bildverarbeitung zur Objekterkennung mittels spezieller neuronaler Netze, die auch als neuronale Faltungsnetzwerke bezeichnet werden. Eine einfache industrielle Bildverarbeitung kann beispielsweise erkennen, ob ein Etikett korrekt auf einer Flasche in einer Hochgeschwindigkeitsabfüllanlage angebracht ist.
Zu den komplexeren Aufgaben gehört das Sortieren von Obst, z. B. Äpfeln, nach Größe, Zustand und Sorte. Bei Echtzeitanwendungen für die Bildverarbeitung im Automobilbereich werden die Algorithmen neuronaler Netze noch komplexer, da sie mehrere Objekte erfassen und klassifizieren müssen. Neuronale Netze werden auch in der wissenschaftlichen Forschung intensiv eingesetzt. So werden beispielsweise riesige Datensätze verarbeitet, um Daten zu analysieren, die von Forschungssatelliten und Erdbebensensoren auf der ganzen Welt gesammelt wurden.
Für die meisten Machine-Learning-Anwendungen müssen Klassifizierungen und Ergebnisse mit einem höheren Grad an Wahrscheinlichkeit vorhergesagt werden. Dafür sind größere Trainingsdatensätze notwendig, was wiederum hohe Anforderungen an das regelmäßige Verschieben, Verarbeiten und Speichern riesiger Datensätze von bis zu 1 PB stellt.
Computational Storage
NAND-Flash-basierte Speicher haben in den letzten zehn Jahren extrem an Popularität gewonnen. Ursprünglich wurden sie nur für High-End-Speicheranwendungen verwendet, doch inzwischen ist die Verwendung von NAND-Speicher für Solid-State-Laufwerke allgegenwärtig und ersetzt in den meisten Laptops und Desktop-Computern die klassischen Magnetfestplatten. Dieser Speicheransatz in Verbindung mit dem Aufkommen des Non-Volatile Memory Express (NVMe)-Protokolls und der steigenden Datenrate bei PCIe-Verbindungen eröffnet die Möglichkeit, Speicher- und Rechenressourcen anders zu gestalten. NVMe-Speichertechnologien zeichnen sich durch eine höhere Bandbreite, niedrige Latenzzeiten und höhere Speicherdichten aus.
In einer klassischen Rechnerarchitektur (siehe Abbildung 1) werden die Daten zwischen der Rechen- und der Speicherebene übertragen. Die Rechenressourcen werden verwendet, um die Daten zu bewegen und zu verarbeiten, zu komprimieren und zu dekomprimieren und eine Vielzahl anderer systembezogener Aufgaben auszuführen. Daher belastet der traditionelle Ansatz die verfügbaren Rechenressourcen erheblich.
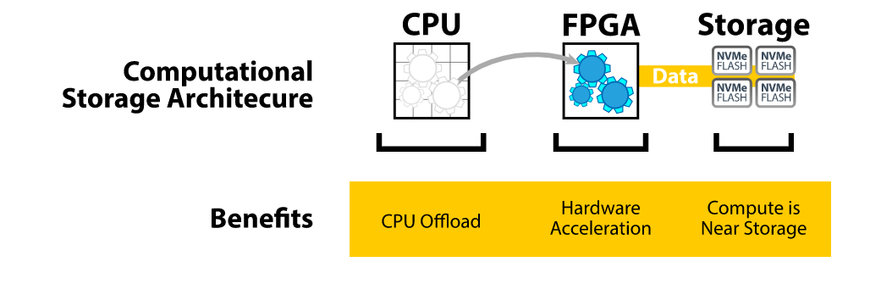
Abbildung 2 – Ein Computational-Storage-Ansatz (Quelle: BittWare)
Ein Ansatz, der rechenintensiver ist, besteht in der Implementierung einer Computational-Storage-Architektur (siehe Abbildung 2). Bei dieser Methode werden die Rechenaufgaben auf einen Hardware-Beschleuniger verlagert, der normalerweise auf einem FPGA basiert. Der Beschleuniger ist mit einem an gleicher Stelle befindlichen NVMe-Flash-Speicher verbunden. Da sich die Daten in der Nähe des Rechenorts befinden, wird die CPU bei der Datenübertragung nicht mehr benötigt und belastet. Der FPGA bildet einen Speicherprozessor (Computational Storage Processor, CSP) (siehe Abbildung 3), auf dem rechenintensive Aufgaben wie Komprimierung, Verschlüsselung oder neuronale Netzwerkinferenz stattfinden, sodass die CPU entlastet werden kann.
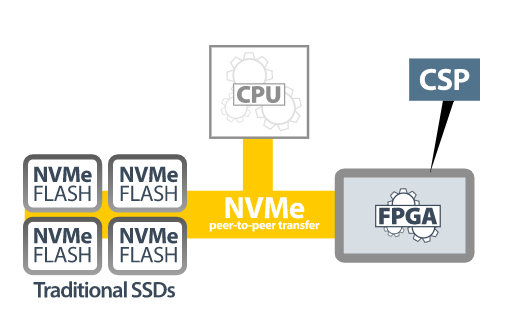
Abbildung 3 – Ein Speicherprozessor (Computational Storage Processor, CSP) (Quelle: BittWare)
Der FPGA-basierte Speicherprozessor IA-220-U2 von BittWare
Ein Beispiel für einen Speicherprozessor ist der IA-220-U2 von BittWare (Mouser-Link?). Der IA-220-U2 besteht aus einem Intel Agilex FPGA mit bis zu 1,4 M Logikelementen, bis zu 16 GB DDR4 Speicher und vier PCIe Gen4 Schnittstellen. Der DDR4 SDRAM kann Übertragungsraten von bis zu 2.400 MT/s erreichen. Der IA-220-U2 ist in einem SFF-8639-kompatiblen Gehäuse im 2,5-Zoll-U.2-Formfaktor mit Konvektionskühlung untergebracht und für den Einbau in ein U.2-NVMe-Speicherarray konzipiert (siehe Abbildung 4).

Abbildung 4 – Der BittWare IA220-U2 ist für den Einbau in ein standardmäßiges U.2-Speicher-Array-Gehäuse konzipiert (Quelle: BittWare)
Er ist Hot-Swapping-fähig und hat einen typischen Stromverbrauch von bis zu 20 Watt, der von der U.2-Host-Stromversorgung geliefert wird. Durch einen integrierten NVMe-MI-kompatiblen SMBus-Controller, eine SMBus-FPGA-Flash-Steuerungsfunktion und SMBus-Zugriff auf integrierte Spannungs- und Temperaturüberwachungssensoren kann der BittWare IA-220-U2 in der Unternehmens-IT und in Rechenzentren eingesetzt werden.
Abbildung 5 zeigt ein funktionales Blockdiagramm des BittWare IA-220-U2, das alle wichtigen Funktionen veranschaulicht.
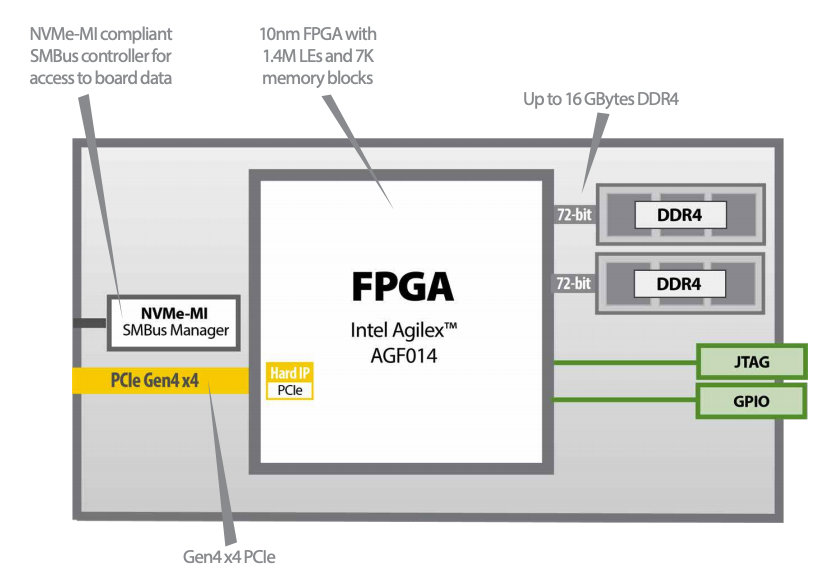
Abbildung 5 - Funktionales Blockdiagramm des BittWare IA-220-U2 (Quelle: BittWare)
Der IA-220-U2 ist für ein breites Spektrum an hochvolumigen Anwendungs- und Beschleunigungsaufgaben ausgelegt, von der Inferenzierung von Algorithmen, Komprimierung, Verschlüsselung und Hashing über die Bildsuche und Datenbanksortierung bis hin zur Deduplizierung.
CSP-Implementierung mit dem BittWare IA-220-U2
Der BittWare IA-220-U2 kann kundenseitig individuell programmiert oder als vorkonfigurierte Lösung unter Verwendung der NoLoad IP von Eideticom geliefert werden.
BittWare stellt ein SDK zur Verfügung, das PCIe-Treiber, Board-Monitoring-Utilities und Board-Bibliotheken zur Unterstützung kundenspezifischer Entwicklungen enthält. Darüber hinaus ist die Entwicklung von FPGA-Anwendungen mit Intels Quartus Prime Pro und High-Level-Synthese-Toolchains und Design-Flows möglich.
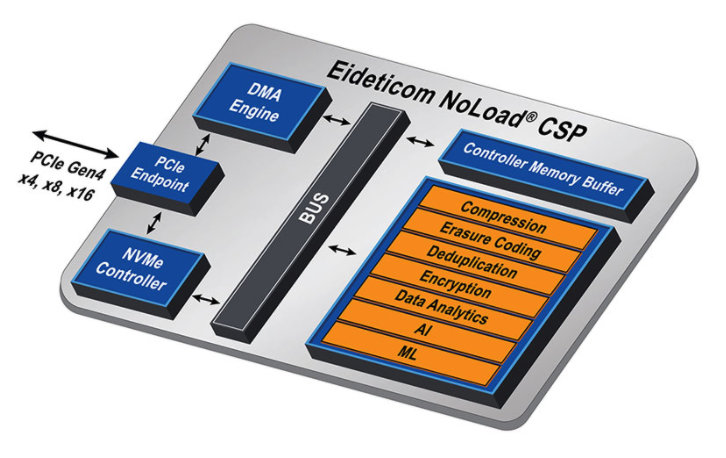
Abbildung 6 – Die Eideticom NoLoad IP Hardware-Funktionen (Quelle: BittWare)
Die NoLoad IP von Eideticom umfasst einen kompletten integrierten Plug-and-Play-Software-Stack, der auf dem BittWare U.2-Modul als vorkonfigurierter Lösung basiert. Sie enthält eine Reihe von hardwarebeschleunigten Computational Storage Services (CSS) (siehe Abbildung 6, orange gekennzeichnet).
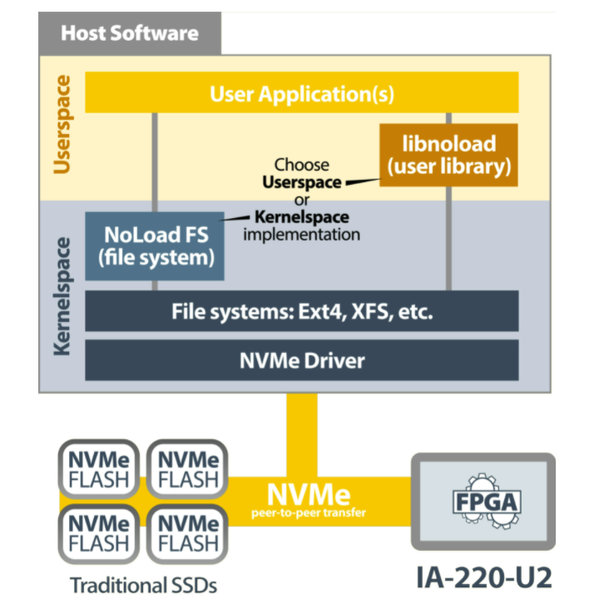
Abbildung 7 – NoLoad IP Software-Stack von Eideticom (Quelle: BittWare)
Die NoLoad IP-Softwarekomponenten (siehe Abbildung 7) beinhalten ein Stacking-Dateisystem im Kernelbereich und einen NVMe-Treiber, der die NoLoad-CSSs nutzt, sowie den anwendungsorientierten Benutzerbereich Libnoload.
Mit der CPU-unabhängigen NoLoad-Lösung von Eideticom lässt sich die QoS durch die CPU-Offload-Funktionen um das bis zu 40-fache verbessern und gleichzeitig lassen sich die Gesamtbetriebskosten und der Stromverbrauch senken.
Datendurchsatz durch Auslagerung rechenintensiver Aufgaben beschleunigen
Die Implementierung einer Computational-Storage-Architektur mit NVMe bietet erhebliche Vorteile in Bezug auf Leistung und Energieeffizienz bei der Verarbeitung großer Datenmengen. Mit diesem Ansatz müssen weniger Daten vom Speicher zur CPU und wieder zurück übertragen werden, da rechenintensive Aufgaben auf einen FPGA-basierten Speicherprozessor ausgelagert werden. Stattdessen werden die Daten auf NVMe-NAND-Flash-Speicher-Arrays in der Nähe des Verarbeitungsortes gespeichert, was die erforderliche Bandbreite reduziert, die Latenzzeit verringert und den Energieverbrauch senkt.
www.mouser.com
Fordern Sie weitere Informationen an…
